OpenAI vừa công bố hợp tác với AMD, NVIDIA, Intel, Microsoft và Broadcom để phát triển giao thức mạng mới mang tên MRC, giúp các cụm GPU quy mô lớn hoạt động nhanh hơn và ít bị gián đoạn hơn khi huấn luyện AI.
Liên minh năm hãng công nghệ hàng đầu này đã dành hai năm cùng nhau xây dựng MRC (Multipath Reliable Connection, kết nối đa đường đáng tin cậy). Giao thức được công bố chính thức thông qua tổ chức OCP (Open Compute Project) để bất kỳ công ty AI nào cũng có thể áp dụng miễn phí, không bị ràng buộc vào một nhà cung cấp cụ thể.

Khi huấn luyện các mô hình AI lớn, hàng chục nghìn GPU phải liên tục trao đổi dữ liệu với nhau theo thời gian thực. Vấn đề nằm ở chỗ: chỉ cần một gói dữ liệu đến chậm, toàn bộ hệ thống phải dừng lại để chờ, đồng nghĩa với việc hàng nghìn GPU đắt tiền ngồi không trong khoảnh khắc đó. Nguyên nhân gây ra sự chậm trễ này chủ yếu là tắc nghẽn mạng, lỗi đường truyền hoặc lỗi thiết bị phần cứng. Và vấn đề càng nghiêm trọng hơn khi quy mô cụm máy chủ càng lớn.
MRC thay đổi cách tổ chức mạng từ gốc rễ. Thay vì xử lý một cổng kết nối tốc độ cao như một đường duy nhất, giao thức này chia nhỏ thành nhiều đường song song đi qua các thiết bị chuyển mạch khác nhau. Ví dụ, một cổng mạng 800 Gb/s có thể được tách thành tám kết nối 100 Gb/s, mỗi kết nối đi qua một thiết bị chuyển mạch riêng biệt. Dữ liệu từ đó được truyền đồng thời qua nhiều hướng, và nếu một đường xảy ra sự cố, hệ thống tự động chuyển hướng trong vòng chưa đầy một phần triệu giây mà không cần can thiệp thủ công.
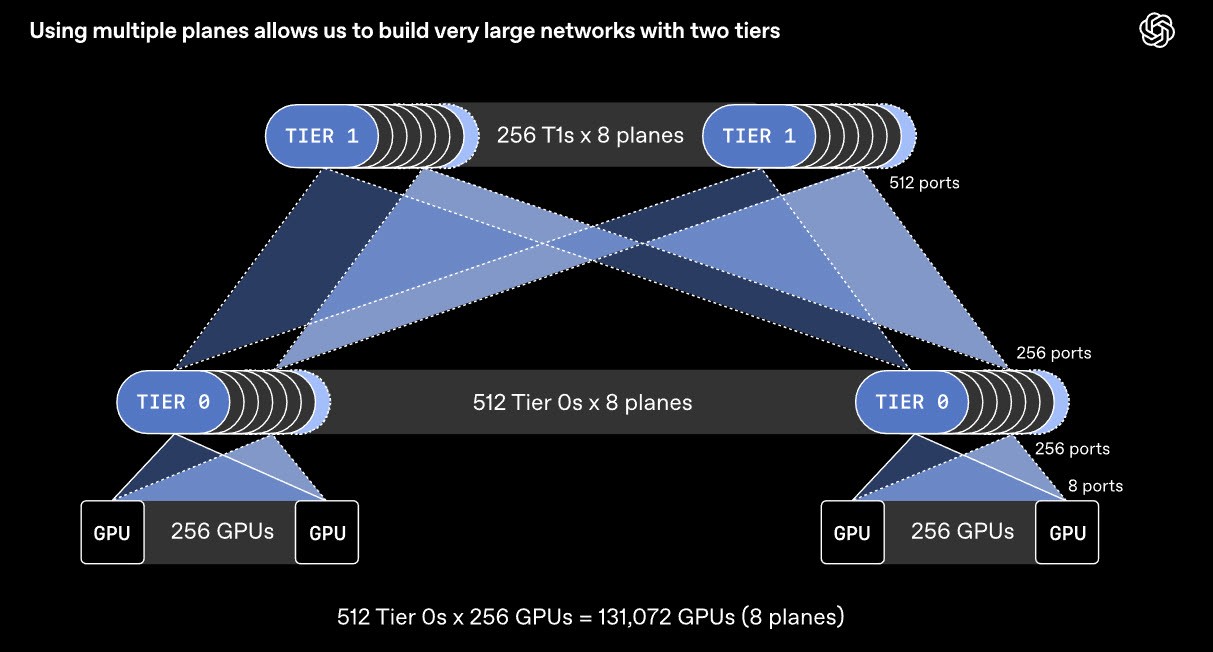
Cách tiếp cận này kéo theo thay đổi đáng kể về hạ tầng. Cùng một thiết bị chuyển mạch, thay vì kết nối 64 cổng ở 800 Gb/s, nay có thể kết nối tới 512 cổng ở 100 Gb/s. Nhờ đó, có thể xây dựng mạng kết nối khoảng 131.000 GPU chỉ với hai tầng thiết bị chuyển mạch, thay vì ba hoặc bốn tầng như kiến trúc thông thường, vừa đơn giản hơn, vừa tiết kiệm chi phí hạ tầng đáng kể.
Về mặt kỹ thuật, MRC được xây dựng trên nền tảng RDMA over RoCE (Converged Ethernet), chuẩn cho phép GPU và CPU truyền dữ liệu trực tiếp vào bộ nhớ của nhau mà không cần CPU xử lý trung gian, qua đó giảm độ trễ và tăng băng thông hiệu dụng. Giao thức được tích hợp sẵn vào các card mạng thế hệ mới ở tốc độ 800 Gb/s.

OpenAI cho biết MRC đã được đưa vào vận hành thực tế trên các siêu máy tính nội bộ đang sử dụng GPU NVIDIA GB200 "Blackwell", dòng chip được dùng để huấn luyện các mô hình AI tiên tiến nhất của hãng. Các hệ thống này bao gồm cơ sở hạ tầng của Oracle tại Abilene, Texas và các siêu máy tính Fairwater của Microsoft. Đến nay, MRC đã được dùng để huấn luyện nhiều mô hình AI khác nhau trên phần cứng của cả NVIDIA lẫn Broadcom.
Giao thức này cũng sẽ là nền tảng mạng cốt lõi của dự án siêu máy tính Stargate mà OpenAI đang xây dựng cùng Oracle tại Abilene, Texas. Stargate đặt mục tiêu đạt công suất tính toán 10 GW vào năm 2029, và đã vượt mốc 3 GW chỉ trong ba tháng triển khai đầu tiên.
Nguồn tin: genk.vn
Những tin mới hơn
Những tin cũ hơn
 Facebook trả tiền cho người dùng Việt Nam
Facebook trả tiền cho người dùng Việt Nam Hàn Quốc định đánh bại OpenAI, Google bằng trí tuệ nhân tạo nội địa như thế nào?
Hàn Quốc định đánh bại OpenAI, Google bằng trí tuệ nhân tạo nội địa như thế nào? 4 câu lệnh tạo ảnh profile “tuyệt đối điện ảnh” bằng Gemini AI
4 câu lệnh tạo ảnh profile “tuyệt đối điện ảnh” bằng Gemini AI OpenAI vừa vá gấp lỗ hổng bảo mật nghiêm trọng trong ChatGPT
OpenAI vừa vá gấp lỗ hổng bảo mật nghiêm trọng trong ChatGPT Google ra mắt mô hình AI Gemini 2.5 dùng trình duyệt như người thật
Google ra mắt mô hình AI Gemini 2.5 dùng trình duyệt như người thật Công nghệ 5/10: Mỹ mua Grok AI của Elon Musk với giá siêu rẻ
Công nghệ 5/10: Mỹ mua Grok AI của Elon Musk với giá siêu rẻ FPT mở chương trình đào tạo thạc sĩ ứng dụng AI vào phân tích dữ liệu kinh doanh
FPT mở chương trình đào tạo thạc sĩ ứng dụng AI vào phân tích dữ liệu kinh doanh AI lên một level mới: Tự nhận ra mình đang bị con người "thử lòng"
AI lên một level mới: Tự nhận ra mình đang bị con người "thử lòng" FPT bắt tay hai công ty Mỹ đưa AI “vào guồng” trong lĩnh vực bảo hiểm và đầu tư tư nhân
FPT bắt tay hai công ty Mỹ đưa AI “vào guồng” trong lĩnh vực bảo hiểm và đầu tư tư nhân Giải pháp mua thẻ game online uy tín, tiện lợi cho game thủ hiện đại từ Zalopay
Giải pháp mua thẻ game online uy tín, tiện lợi cho game thủ hiện đại từ Zalopay